Despite recent advances in diffusion models, top-tier text-to-image (T2I) models still struggle to achieve precise spatial layout control, i.e. accurately generating entities with specified attributes and locations. Segmentation-mask-to-image (S2I) generation has emerged as a promising solution by incorporating pixel-level spatial guidance and regional text prompts. However, existing S2I methods fail to simultaneously ensure semantic consistency and shape consistency. To address these challenges, we propose Seg2Any, a novel S2I framework built upon advanced multimodal diffusion transformers (e.g. FLUX). First, to achieve both semantic and shape consistency, we decouple segmentation mask conditions into regional semantic and high-frequency shape components. The regional semantic condition is introduced by a Semantic Alignment Attention Mask, ensuring that generated entities adhere to their assigned text prompts. The high-frequency shape condition, representing entity boundaries, is encoded as an Entity Contour Map and then introduced as an additional modality via multi-modal attention to guide image spatial structure. Second, to prevent attribute leakage across entities in multi-entity scenarios, we introduce an Attribute Isolation Attention Mask mechanism, which constrains each entity’s image tokens to attend exclusively to themselves during image self-attention. To support open-set S2I generation, we construct SACap-1M, a large-scale dataset containing 1 million images with 5.9 million segmented entities and detailed regional captions, along with a SACap-Eval benchmark for comprehensive S2I evaluation. Extensive experiments demonstrate that Seg2Any achieves state-of-the-art performance on both open-set and closed-set S2I benchmarks, particularly in fine-grained spatial and attribute control of entities.
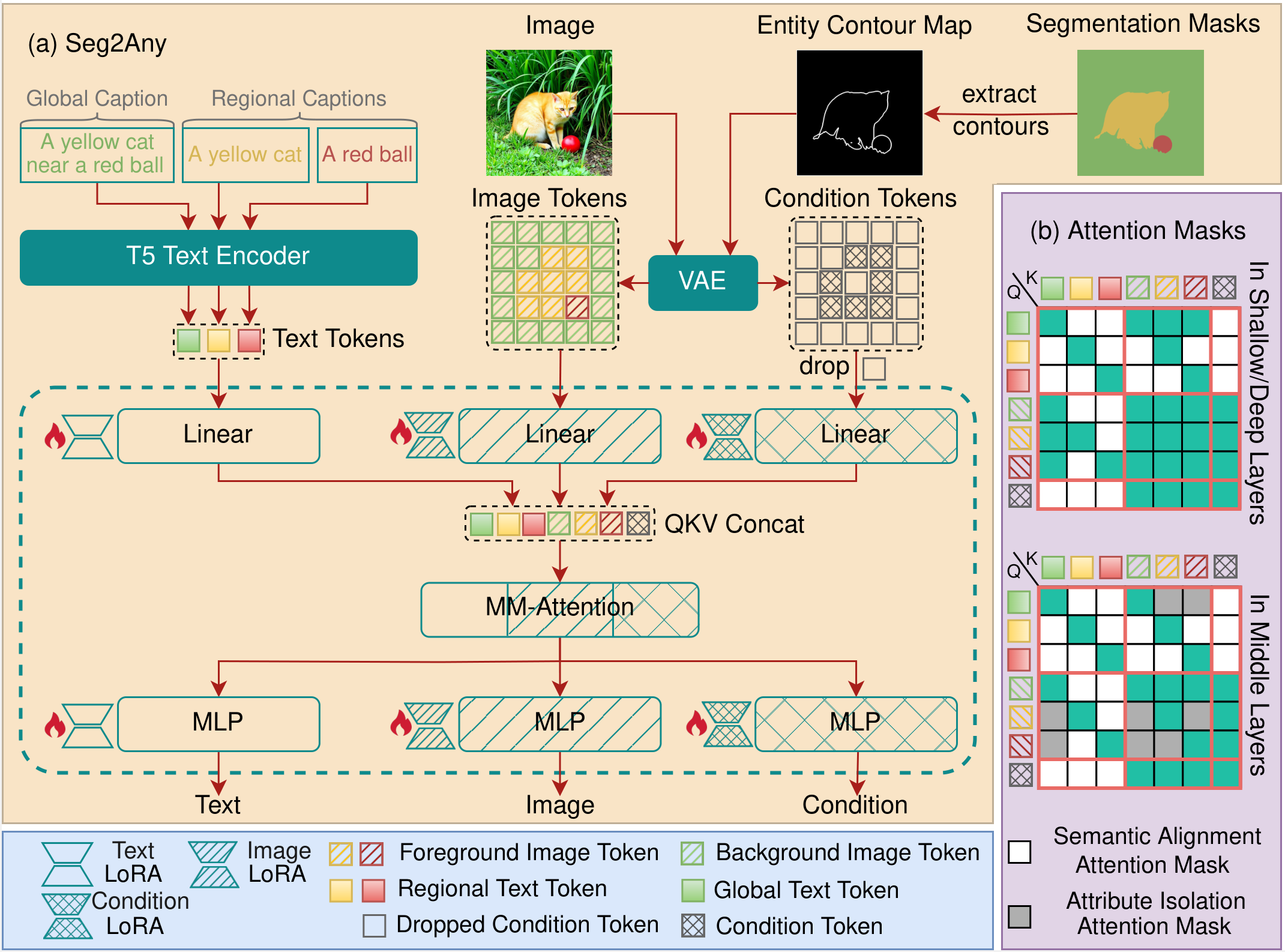
(a) An overview of the Seg2Any framework. Segmentation masks are transformed into Entity Contour Map, then encoded as condition tokens via frozen VAE. Negligible tokens are filtered out for efficiency. The resulting text, image, and condition tokens are concatenated into a unified sequence for MM-Attention. Our framework applies LoRA to all branches, achieving S2I generation with minimal extra parameters. (b) Attention Masks in MM-Attention, including Semantic Alignment Attention Mask and Attribute Isolation Attention Mask.
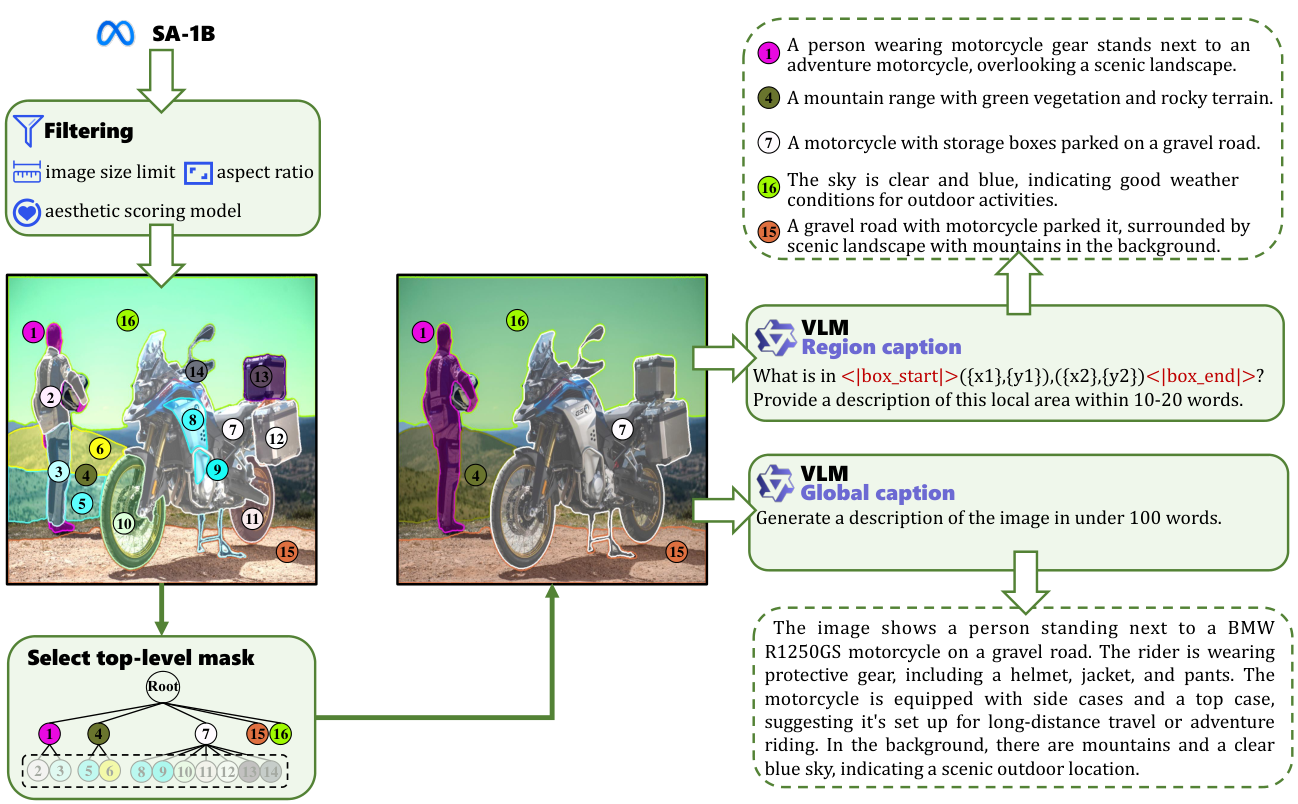
An overview of the data annotation pipeline. Recent advances in open-source vision language models (VLMs), such as Qwen2-VL-72B, have significantly reduced the performance gap with close-source VLMs like GPT-4V, making it feasible to create large-scale and richly annotated datasets. Leveraging the capabilities of Qwen2-VL-72B, we construct Segment Anything with Captions 1 Million (SACap-1M), a large-scale dataset derived from the diverse and high-resolution SA-1B dataset. SACap-1M contains 1 million image-text pairs and 5.9 million segmented entities, each comprised of a segmentation mask and a detailed regional caption, with captions averaging 58.6 words per image and 14.1 words per entity. We further present the SACap-Eval, a benchmark for assessing the quality of open-set S2I generation.
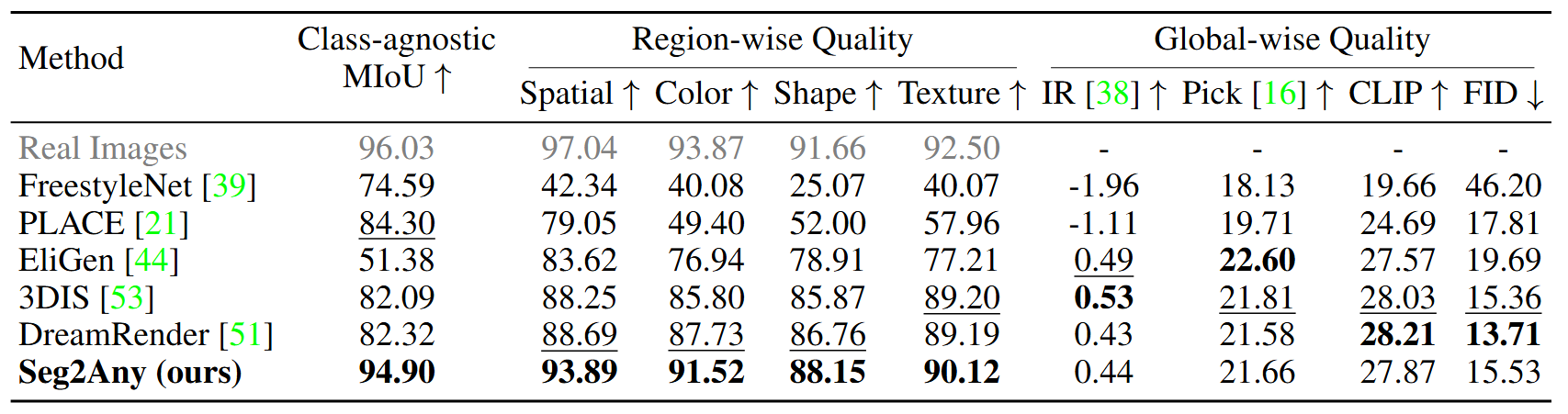
Quantitative comparison on the SACap-Eval benchmark. Bold and underline represent the best and second best methods, respectively.
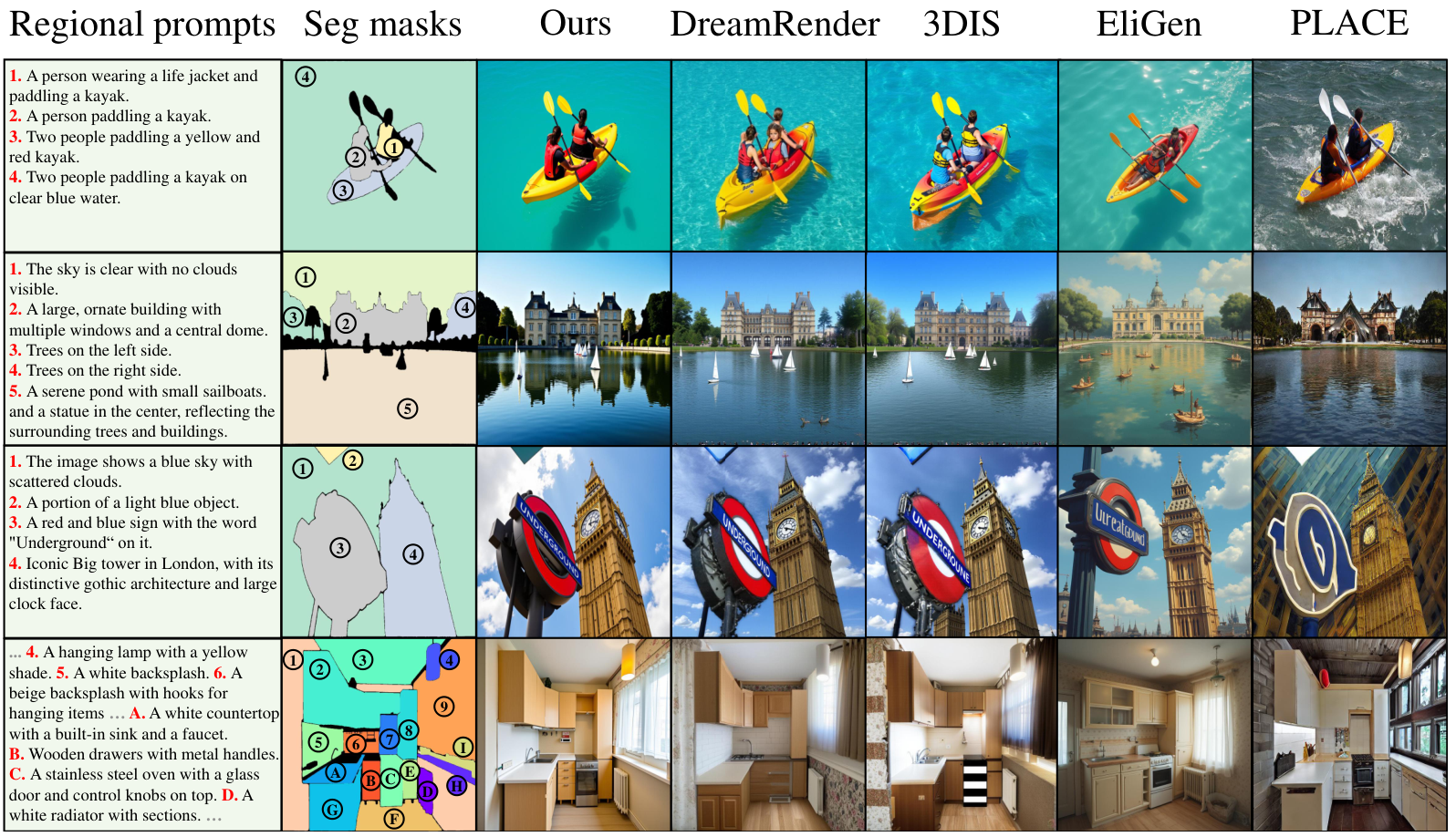
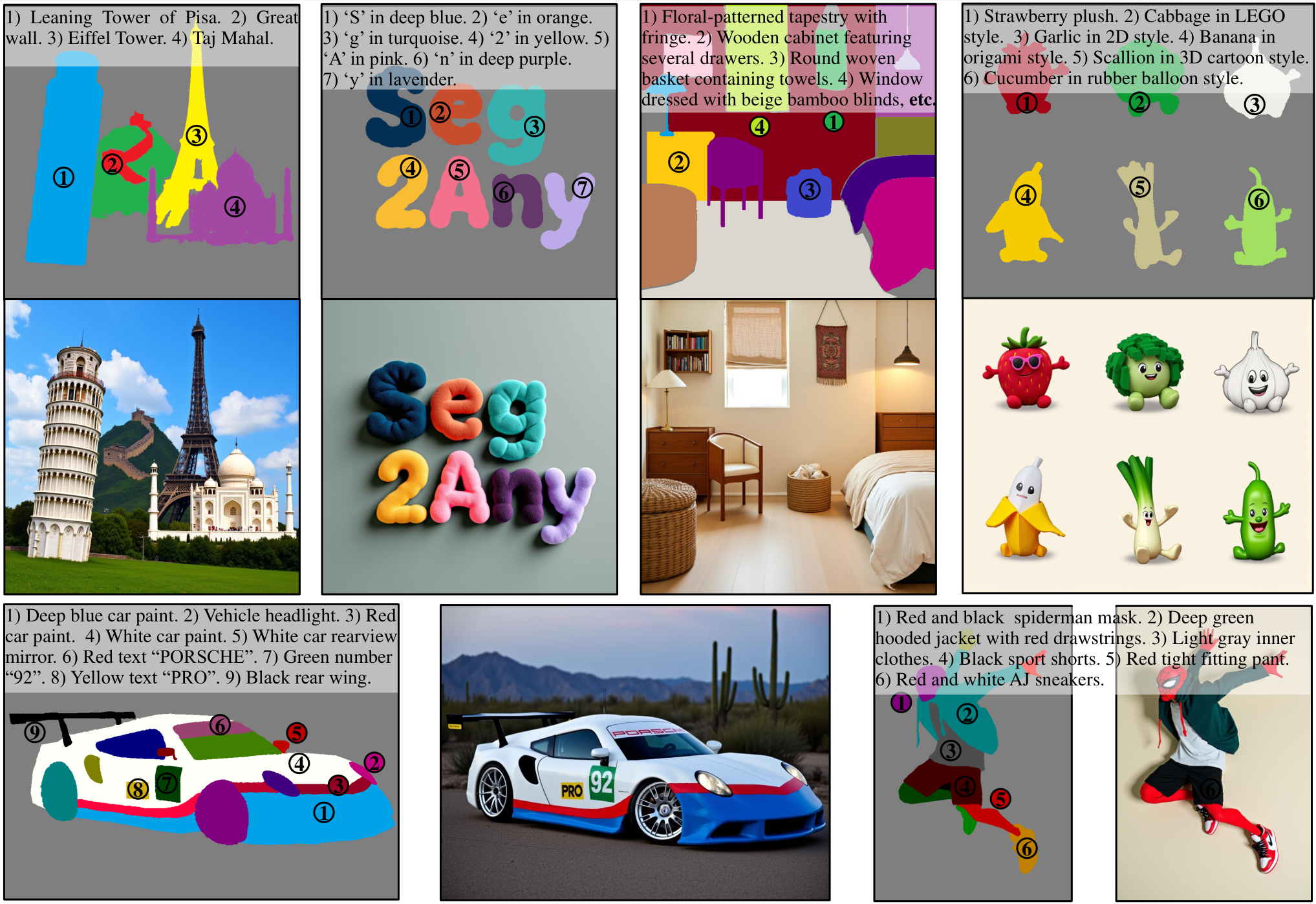
Qualitative comparisons on SACap-Eval. Seg2Any accurately generates entities exhibiting complex attributes such as color and texture, surpassing previous approaches.
@article{li2025seg2any,
title={Seg2Any: Open-set Segmentation-Mask-to-Image Generation with Precise Shape and Semantic Control},
author={Li, Danfeng and Zhang, Hui and Wang, Sheng and Li, Jiacheng and Wu, Zuxuan},
journal={arXiv preprint arXiv:2506.00596},
year={2025}
}
